Алгоритм BASE64 и собственная реализация на .NET
С самого раннего своего компьютерного детства я весьма плотно и серьёзно полюбил алгоритмы. Да, собственно, чего уж — я их люблю до сих пор. Но ещё больше мне нравится когда они красивые и такие, что можно понять за одно прочтение 🙂 И сегодня как раз об одном из таких алгоритмов и пойдёт речь: удивительно простой и математически красивый подход к шифрованию. Сегодня мы разберём Base64 и поговорим о том, что это такое, для чего был создан, где использовать и как работает.
Уже не в первый раз сталкиваюсь с тем, что с одной стороны огромное количество программистов используют base64 в повседневной жизни и, с другой стороны — лишь малая толика из них знает о том, как «под капотом» в нём внутри всё устроено. А это, действительно, очень интересный пример математическое красоты и самой концепции и идеи.
Зачем и где нам это нужно и где может понадобится?
Итак, base64, если очень коротко — это алгоритм кодирования (и обратного декодирования) любой байтовой информации в тестовую строку. На входе мы отдаём свой произвольный байт массив и на выходе получаем строку. При декодировании, наоборот — подаём строку, получаем свой байт массив. Т.е. получается, что мы можем любую информацию привести к тексту (латинскому алфавиту в двух регистрах,а также цифры).
Существует множество текстовых протоколов изначально не предназначенных для передачи бинарной информации. Самыми первыми таковыми форматами стала электронная почта и, собственно, первый интернет по http. И если в первое время простого текста было уже достаточно, то через совсем короткий срок всплыла острая необходимость передачи двоичных бинарных данных, т.е. возможность принимать и отсылать любые файлы в тех условиях, которые были — т.е. в тексте.
Появляется понятие транспортного кодирования, т.е. такого форматирования данных, которое может быть совместимо с текущими протоколами передачи данных. Основной проблемой подобного транспорта байт заключалось в первых 32 символах ASCII (контрольные служебные символы, символы переноса строки и т.д.), т.е. тех байт, которые могли быть не верно интерпретированы самими текстовыми протоколами или вовсе сломать их. Другими словами невозможно отделить CRLF как часть протокола или уже передаваемого файла. Нужна была дополнительная абстракция, в которую это всё можно было бы аккуратно завернуть.
Современный мир вполне себе придумал различные альтернативные способы доставки бинарных данных, но base64 всё ещё актуален и активно используется. К примеру, вы можете передать картинку в HTML (или CSS) без помощи указания пути на внешний файл, а прям в самой разметке страницы в виде текста (в примере указана полноценная PNG картинка небольшого красного кружочка 10×10 пикселей):
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgA AAAoAAAAKCAYAAACNMs+9AAAABmJLR0QA/wD/AP+gvaeTAAAAB3RJ TUUH1ggDCwMADQ4NnwAAAFVJREFUGJWNkMEJADEIBEcbSDkXUnfSg nBVeZ8LSAjiwjyEQXSFEIcHGP9oAi+H0Bymgx9MhxbFdZE2a0s9kT Zdw01ZhhYkABSwgmf1Z6r1SNyfFf4BZ+ZUExcNUQUAAAAASUVORK5 CYII="/>
Кроме современного веба, HTML и CSS, base64 часто можно встретить в конфигурационных файлах JSON или XML, с целью кодирования какой-либо зашифрованной байтовой информации в доступный для передачи удобный текстовый вид.
Идея base64
В изобретённой в 1963 году ASCII таблице изначально планировалось использовать 7-битовую кодировку, которой хватало на 128 символов (чуть позже появилась расширенная таблица на 8 бит и 256 символов, которая включала уже разнообразные национальные буквы и дополнительные языковые конструкции). Позже Unicode унаследовала первые 128 символов ASCII и тем самым это всё стало ещё более универсальным стандартом для всех. Вот так же выглядела таблица в начале времён (кстати, у меня есть сайт asciihex.com, на котором есть информация о практически каждом символе таблицы):
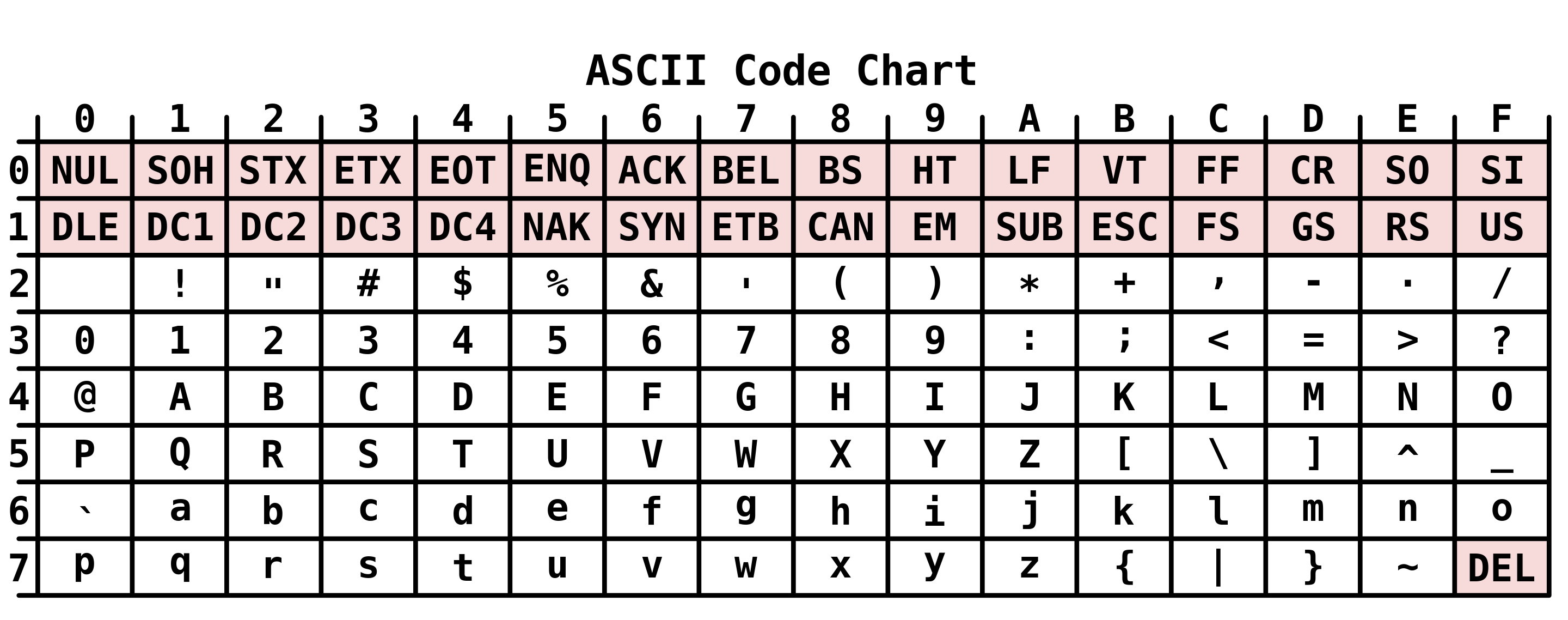
Теперь давайте поговорим про байт. Все мы знаем, что в одном байте располагается 8 корзин бит (это весьма случайная история и так было не всегда, но тем не менее). Т.е. набор из только 8 возможных вариантов нулей или же единиц, комбинации которых позволяют получить десятичное число от 0 до 255. Удачное совпадение с ASCII, не правда ли? 🙂
Суть идеи кодирования и декодирования base64 заключается в том, что мы искусственным образом уменьшаем наши входные байты с 8 до 6 бит, тем самым уменьшая получаемый диапазон с 0-255 до 0-63 и при этом увеличивая объём выходной информации примерно на треть. 64 — это как раз словарь base64 кодировки и выглядит он следующим образом:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
Именно в эти (и только в эти) символы мы сможем кодировать любые наши байты. Данная строка является константой для стандарта base64, хотя в своей реализации вы вольны изменять её каким угодно образом.
Давайте разберём небольшой пример, с которым всё станет более понятно. Возьмём слово DEV (как мой логин в твиттере или название этого блога) и попробуем его перевести в base64 руками. Нам на помощь придёт такая вот табличка:
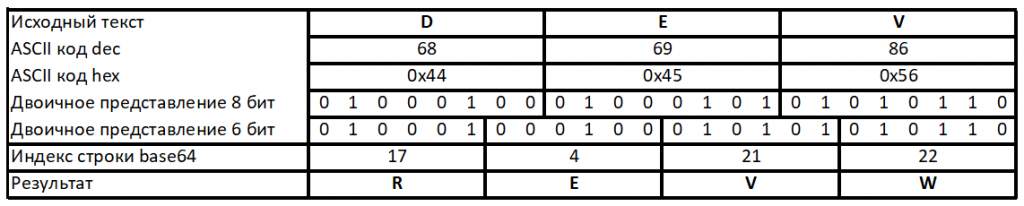
Пройдёмся шаг за шагом по алгоритму. Берём буквы ‘D‘, 'E‘, ‘V‘ и получаем их двоичное представление: 01000100, 01000101 и 01010110. Соберём всё это в одну строку: 010001000100010101010110 и разобьём не на 8 частей, а на 6: 010001, 000100, 010101 и 010110. Полученные четыре части переведём в десятичную систему: 17, 4, 21, 22 — всё это индексы из строки-словаря выше. Т.е. буквы: ‘R‘, ‘E‘, ‘V‘, ‘W‘. И, действительно, если вы проверите через любой онлайн конвертер строк base64, то получится из DEV — REVW.
Данная ситуация валидна для информации, количество байт которой кратно трём. Т.е. можно ровненько разделить 3 байта 24 бита на 4 «отрезка» по 6 бит. В случаях, когда данные не кратны трём — мы завершаем строку знаком равно (одни или двумя, в зависимости от изначального количества входных данных). Таким образом слово devellloper кодируется в ZGV2ZWxsbG9wZXI= с одним знаком равенства потому, что в нашем изначальном слове 11 букв (3 кусочка по 3 байта и 1 кусочек на 2 байта, один не полный заменяется равенством).
Декодирование похоже и является обратным алгоритмом от кодирования. Мы берём закодированные буквы, на рассматриваемом выше примере это текст REVW — переводим каждый символ в десятичный код: 17, 4, 21, 22. Полученные числа переводим в двоичное представление, получаем всё тот же набор из бит 010001000100010101010110, который делим на три части и переводим их в десятичную систему, для того чтобы узнать код ASCII — получаем наши исходные байты D, E, V.
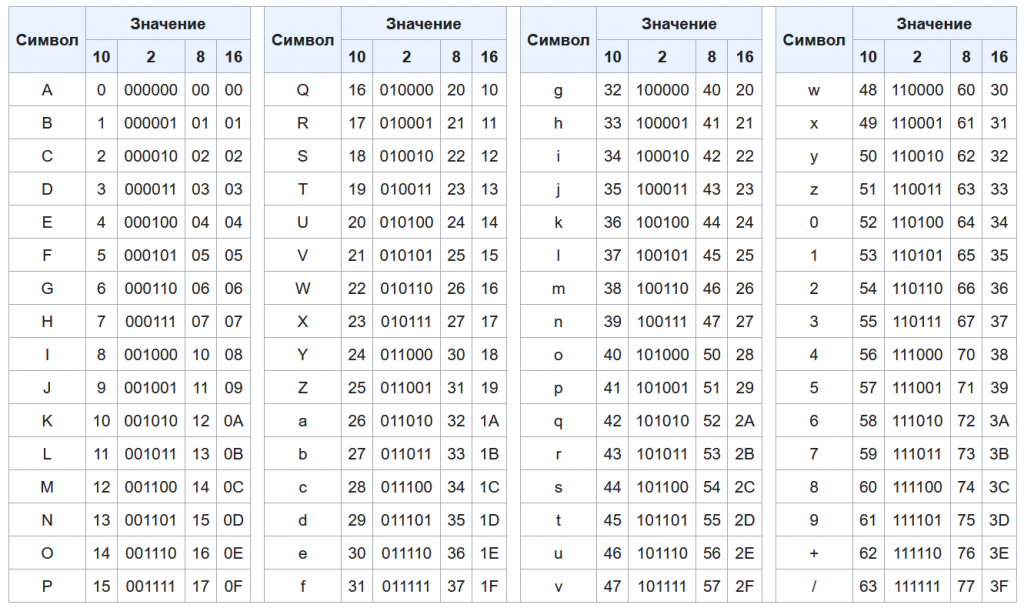
Как видите, ничего сложного (надеюсь 🙂 ). Для быстроты и удобства (если уж вы решили кодировать-декодировать на бумажке) можно использовать подобную табличку:
Пишем собственную реализацию на .NET C#
Давайте напишем собственный простенький кодировщик base64 на языке С#. Я решил написать его в императивном стиле (как в старые добрые BASIC времена), без валидаций аргументов и больше с целью демонстрации, чем использования где-либо в проде. Тем более для этого есть прекрасный нативный метод Convert.ToBase64String 🙂 Итак, нам понадобится определить некоторые константы и массив с символами для кодирования:
public const int COUNT_ENCODE_BYTES = 3; public const int COUNT_BITS = 24; public const int COUNT_ENCODE_BITS = 6; public const int COUNT_DECODE_BITS = 8; public static readonly char[] AR = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".ToCharArray();
Теперь напишем все необходимые для нашей работы методы:
public static string ToBin(byte[] data) => string.Join(string.Empty, data.Select(b => Convert.ToString(b, 2).PadLeft(8, '0')));
public static string ToBin(string data) => ToBin(Encoding.UTF8.GetBytes(data));
public static string[] Split(string bin, int count)
{
if (bin.Length != COUNT_BITS)
throw new ArgumentException(nameof(bin));
List<string> result = new List<string>();
StringBuilder sb = new StringBuilder();
for(int i = 0; i < COUNT_BITS; i++)
{
sb.Append(bin[i]);
if(sb.Length == count)
{
result.Add(sb.ToString());
sb.Clear();
}
}
return result.ToArray();
}
public static int[] BinToInt(string[] data)
{
List<int> result = new List<int>();
foreach(string c in data)
result.Add(Convert.ToInt32(c, 2));
return result.ToArray();
}
public static int GetCountOfEquals(string data)
{
int mod = data.Length % COUNT_ENCODE_BYTES;
if (mod == 0)
return 0;
return COUNT_ENCODE_BYTES - mod;
}
public static string GetDataFromQueue(Queue<char> q)
{
StringBuilder sb = new StringBuilder();
while (q.Count > 0)
sb.Append(q.Dequeue());
return sb.ToString();
}
public static string Process(Queue<char> q)
{
string data = GetDataFromQueue(q);
string bin = ToBin(data).PadRight(COUNT_BITS, '0');
string[] parts = Split(bin, COUNT_ENCODE_BITS);
int[] index = BinToInt(parts);
StringBuilder sb = new StringBuilder();
foreach (int i in index)
sb.Append(AR[i]);
return sb.ToString();
}
В принципе, конечно, здесь ничего сложного нет, но я всё-таки разъясню. ToBin — два перегруженных метода для конвертации строки в двоичных код (тоже строку, но из нулей и единиц), Split — делим строку на равные кусочки строк, BinToInt — получаем из массива строк, состоящих из нулей и единиц в массив чисел (т.е. переводим двоичный код в десятичную систему), GetCountOfEquals — количество символов =, которые необходимо добавлять к строке, GetDataFromQueue — получаем строку из очереди char, Process — переводим из порции символов из очереди в base64.
Теперь у нас всё готово для того, чтобы мы смогли конвертировать входящую строку в закодированную base64 строку. Для этого реализуем следующий метод Encode:
public static string Encode(string data)
{
Queue<char> q = new Queue<char>();
StringBuilder sb = new StringBuilder();
foreach(char c in data)
{
if (q.Count == COUNT_ENCODE_BYTES)
sb.Append(Process(q));
q.Enqueue(c);
}
if (q.Count > 0)
{
sb.Append(Process(q));
int e = GetCountOfEquals(data);
sb.Remove(sb.Length - e, e);
sb.Append(new string('=', e));
}
return sb.ToString();
}
Для того, чтобы всё это проверить я написал небольшой тест (их там несколько, но здесь я привожу только сам метод Encode):
private string Encode64(string data)
{
byte[] b = Encoding.UTF8.GetBytes(data);
return Convert.ToBase64String(b);
}
[TestMethod]
public void EncodeTest()
{
//Arrange
string t1 = "DEV";
string t2 = "DE";
string t3 = "D";
string t4 = "deve";
string t5 = "devel";
string t6 = "develo";
string t7 = "develop";
string t8 = "develope";
string t9 = "developer";
//Act
string r1 = Base64.Encode(t1);
string r2 = Base64.Encode(t2);
string r3 = Base64.Encode(t3);
string r4 = Base64.Encode(t4);
string r5 = Base64.Encode(t5);
string r6 = Base64.Encode(t6);
string r7 = Base64.Encode(t7);
string r8 = Base64.Encode(t8);
string r9 = Base64.Encode(t9);
//Assert
Assert.AreEqual(Encode64(t1), r1);
Assert.AreEqual(Encode64(t2), r2);
Assert.AreEqual(Encode64(t3), r3);
Assert.AreEqual(Encode64(t4), r4);
Assert.AreEqual(Encode64(t5), r5);
Assert.AreEqual(Encode64(t6), r6);
Assert.AreEqual(Encode64(t7), r7);
Assert.AreEqual(Encode64(t8), r8);
Assert.AreEqual(Encode64(t9), r9);
}
Собственно, всё. Тест проходит, конвертация удачная:
Спецификации
Естественно у base64 есть собственная спецификация и она описана в RFC 3548 (как попытка унифицировать и привести к одному подходу предыдущие попытки решить проблему транспорта байт в тексте: RFC 1421 и RFC 2045). Чуть позже RFC 3548 объявляется как устаревший и основным является уже новый и обновлённый RFC 4648, действующий до сих пор.
На этом всё. Надеюсь было интересно. Пишите комментарии — это всегда мотивирует на дальнейшие разборы алгоритмов, структур данных и подобных иных не менее интересных тем.