
Структура данных — Очередь (FIFO, Queue)
Сегодня речь пойдёт о базовой и фундаментальной структуре данных — очереди (Queue). Данная модель (как и любая другая структура данных) является математической абстракцией над повседневной жизнью. Собственно, аналогии из нашего быта — это всё ещё самый лучший способ понять и объяснить основные структуры данных 🙂 Очередь за хлебом или в поликлинику (как социальное явление) — это и есть та самая структура данных очередь. Собственно, и названа поэтому. Смысл прост — кто первым пришёл, тот первым и будет обслужен. Данный принцип скрывается за аббревиатурой FIFO (First In — First Out или ПППО по-русски).
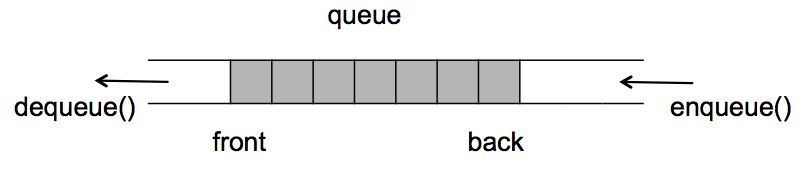
FIFO — важная составляющая не только в информатике, но и в логистике и многих других сферах жизни. Очередь используется сплошь и рядом: любой конвейер, пулемётная лента, однополосная дорога с односторонним движением, проходная на заводе и т.д.. Основной характеристикой очереди является начало (голова) и конец (хвост). Новые элементы добавляются только в конец, а «считывание» происходит исключительно с головы. Если вы приходите первым на почту — вас обслужат первым; если же перед вами до этого стояли люди — вам необходимо дождаться когда будут обслужены все N-впереди стоящие. Один за одним, итерационно. Это называется доступом к элементам очереди.
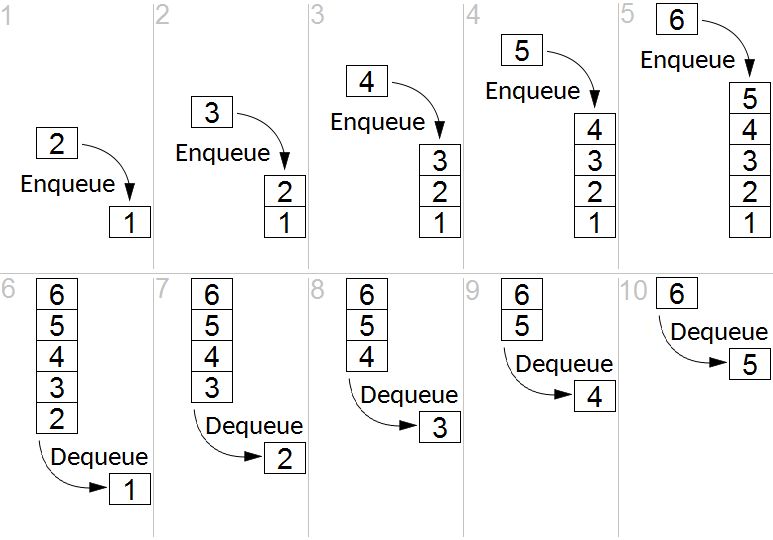
Существуют канонические методы взаимодействия с очередью: Enqueue — добавление элемента в конец очереди, Dequeue — считывание с головы и удаление (очистка) элемента. Также иногда:Peek — считывание с верхушки без удаления, поле Count — кол-во элементов в очереди и метод Clear — для полной очистки.
В последнее время часто происходят споры с какой именно стороны необходимо добавлять новые элементы — в хвост или голову (по аналогии, что еда поступает змее в голову, а не хвост). Отсюда иногда встречаются и такие картинки (с перевернутым направлением, что, практически, сути не меняет):
Существует множество способов реализации структуры данных очередь при помощи практически любых языков программирования. Первый и самый простой способ — при помощи одного массива фиксированного размера и нескольких локальных целочисленных переменных front и rear, где первая указывает на голову очереди, а последняя — на хвост. Алгоритм добавления и считывания в очередь можно описать следующими шагами:
Шаг №1 — объявление переменных:
- Объявим целочисленную переменную
size, в которой будет хранится размер очереди; - Объявляем локальный массив
queueтипаTс необходимой нам размерностью (size); - Объявим две целочисленных локальных переменных
frontиrear, обе равные-1;
Шаг №2 — функция\метод добавления элемента в очередь (enqueue):
- Проверяем не заполнена ли очередь (условие, когда
rear==size-1); - Если очередь заполнена — выбрасываем ошибку;
- Если ещё есть место — инкрементим
rear++и вставляем элемент в массивqueue[rear]=value;
Шаг №3 — функция\метод удаления элемента из очереди (dequeue):
- Проверяем не пустая ли очередь (условие, когда
front==rear); - Если очередь пустая — выбрасываем ошибку;
- Если есть элементы — инкрементим
front++и показываем элемент из массиваqueue[front]=value; - Проверить, если
front==rear, то сбрасываем обе переменные к значению-1;
Шаг №4 — функция\метод удаления элемента из очереди:
- Проверяем не пустая ли очередь (условие, когда
front==rear); - Если очередь пустая — выбрасываем ошибку;
- Если есть элементы — показываем элемент из массива
queue[front+1]=value;
Как видите, всё очень просто. Очередь — это фундамент и её применение подходит во всех случаях, где нужно последовательно производить какую-либо операцию в порядке поступления элементов. Вопрос про очередь очень любят задавать на собеседованиях и, надеюсь, кому-то эта запись будет полезной. В ближайшем будущем постараюсь написать простую реализацию очереди на нативном C# (без использования System.Collections.Generic.Queue), а также перейду к другим базовым структурам данных.